Selecting the right site for a new media production and workspace facility is crucial for…
It has become commonplace in the digital world to talk about the wisdom of the crowd–the aggregated opinions of everybody. The problem is that the crowd isn’t everybody. The crowd is pockets of interest, loud voices, competing truths.
Published in The Huffington Post, October 20, 2015
by Daryl Twitchell, Jeremy Rabson and Kevin McDermott
Living in the information age is amazing. The difficulty is that we can’t always know what actually counts as information.
Like TV in the video age, digital tools spread so rapidly and so pervasively that it’s hard to imagine a time when they didn’t exist. The Internet as a consumer technology is barely 20 years old. Its conventions are still being established. In the meantime we port over the conventions of previous human behavior that don’t always apply — the same as we did with television.
It has become commonplace in the digital world, for example, to talk about the wisdom of the crowd–the aggregated opinions of everybody. The problem is that the crowd isn’t everybody. The crowd is pockets of interest, loud voices, competing truths.
Walk among your Facebook friends and ask for opinions about a car you’re thinking of buying. You will know the lenses through which they see things, providing context for their opinions. This isn’t true of Internet crowds. That’s more like wandering into a cocktail party and not knowing who’s there.
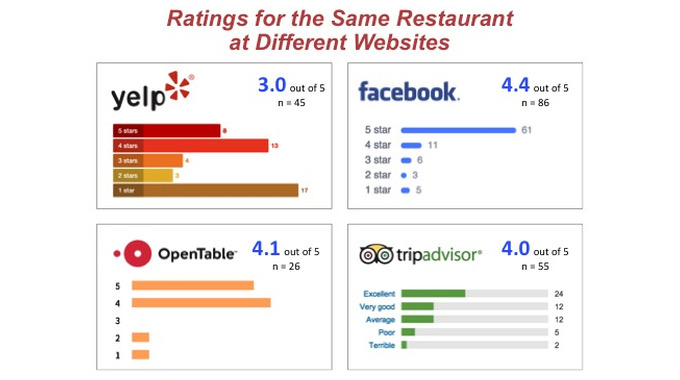
Consider the phenomenon of review sites like Yelp and TripAdvisor, where the same restaurant can get different reviews depending on which site you check. Why? Make a guess. The danger is that people think these opinion-aggregating sites are reporting something factual. This danger is magnified when we lend such crowd-sourced wisdom to investments, markets and politics.
Marketers have begun to wonder, for example, if online surveys are in fact a case of garbage in and garbage out. Pollsters have a similar problem trusting the universes they canvass. The statistician Nate Silver, meanwhile, has built a reputation challenging the conventional pundits who allude to squishy kinds of “data” in the opinions they peddle.
This is not a new problem. Advertisers, for instance, have known for two generations that Nielsen TV ratings are at best a good guess about viewership. And still zillions of dollars change hands on the basis of what Nielsen reports.
A wise crowd. A wise crowd has scale and full participation. How do you tell when that’s true of a digital crowd?
Our first impulse is to get a sense of who is in the crowd by looking for markers. Do the voices in it seem to value the same things, use the same measures we do — do they reflect our truth, in other words? Too often we seize on screwy things like shared cultural references or, worse, pay most attention to the loudest voice. We make these judgments in an instant without even being aware we’re doing it.
Or take sites like Amazon and Yelp which spotlight “top reviewers.” Most likely a top reviewer is someone with a lot of opinions who collects virtual badges of honor (and has too much time on their hands). One study found that residents of Maine and Vermont, for some reason, are represented among Amazon’s top reviewers at rates more than three times their percentage of the U.S. population. In such a system the risk is that, in the aggregate, reviews will skew to the noisy minority.
People tend to express opinion online if they love something or hate it. (That’s ouropinion, by the way. Better check for yourself.) Ever wonder why some restaurants get lots of five stars and ones, but not many twos, threes and fours? We all sort of know this, so we end up picking and choosing what we want to believe is true.
Radical autonomy. The digital life promotes radical autonomy. That means we need new skills and new habits of mind for sifting the quality of digital information. In every case we need to ask what it means to go deeper and be our own data miners. We need to be empirical.
Google, for example, will give you information about who’s searching for information about the flu and where the searches are concentrated. That tells a lot more than a few dozen people who go on Facebook to remark that their kid is home from school and there seems to be flu going around.
Instead of aggregating reviews for a restaurant and handing out stars the way Yelp does it would be more revealing to see empirical performance data about the place.OpenTable, for example, knows the demand for tables at every one of the restaurants in its database. If we want to know whether people are voting with their feet we could find out what percentage of tables are full every night and call up a trend line. That might predict a lot more about your enjoyment than the opinions of 23 reviewers who give the place an aggregate 3.4 stars.
If demand grows for more rigor products will respond. We’ll get better — or our tools will — at pattern recognition, rather the way Netflix uses an algorithm to identify people with similar tastes — not by asking but by parsing real data.
In the meantime, better than a “top reviewer’s” opinion is the structure of an Amazon product page, which tells users what other shoppers interested in the same product looked at and eventually bought. That’s based on behavior, not opinion. Imagine if Amazon also shared the return rate on every product it sold — and the reasons for returns. Wouldn’t that be more useful than the opinions of anonymous reviewers motivated who knows why?
The best approach is not cynicism but skepticism. Consider your source. Who sponsors the thing? Who does it attract? Learn to triangulate sources, just as sophisticated consumers of news read about the same story from several outlets to understand an event in three dimensions.
Most of us are still amateurs at making sense of information (unlike the professionals who know good data from bad and capitalize on that difference). Given a little more time living in the digital world we’ll all get better at knowing fact from hot air.
Related Insights


